In the past three years, we at EdgeLab have been working on the problem of building edge-cloud systems — systems that span both cloud and edge computing infrastructure. Our focus on this edge-cloud architecture is due to that it appeared to us that it is a promising way to enable emerging real-time edge and IoT applications that require both fast response (that we may get by placing resources close to users at the edge) and high-performance compute and integrity (that we may get from cloud resources). These applications — such as ones based on interactive and collaborative mobile applications, Augmented/Virtual Reality, and smart vehicles/drones — are incredibly cool and have undergone extensive research for decades. However, we believe that there is a technology gap that is standing between the advances made in these applications and exploring their full potential in real-life applications; that gap is the lack of data management systems that are designed specifically for an edge-cloud architecture, enabling these applications access to an illusion of both fast and high-performance compute.
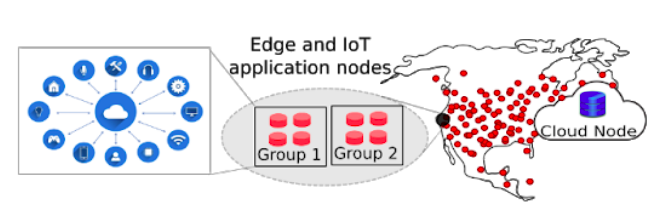
This observation has been made by many other teams as well and has resulted in research and prototypes that are exploring this space of edge-cloud systems. In this year’s CIDR, authors of VergeDB argue that the emergence of IoT applications requires “a significant amount of data processing to happen on edge devices” [1]. However, they observe that their edge-based system is not going to be performing all tasks of the overall system, rather, that the edge-based system should work cooperatively with the cloud system by performing in-situ analytics and compression. Likewise, Neurosurgeon’s authors explore edge-cloud cooperative processing for deep neural networks, where it is found that splitting the layers of a deep neural network into an edge part and a cloud part yields better performance and energy efficiency [2]. These examples, and many others, explore edge-cloud cooperative processing and demonstrate the efficacy of such an architecture for analytics and machine learning-based workloads. However, the opportunities of edge-cloud computing go beyond these applications.
The most recent Seattle Report on Database Research [3] motivates the opportunities in edge-cloud systems in two forms. The first is under the heading “Edge and cloud”, where it argues for the need for novel data processing and analytics techniques to accommodate the proliferation of IoT devices with limited capabilities. The second is under the heading “Hybrid cloud” where it argues for the need for new seamless systems that enable “on-premise” (which may represent an edge deployment) and cloud systems to work cooperatively. These two forms highlight the two main challenges in building edge-cloud systems: (1) the asymmetry of the capability of resources on the edge and on the cloud, and (2) the need for designing a single control plane that seamlessly connects edge and cloud resources.
These challenges motivated our work in EdgeLab, where we study distributing systems across edge and cloud resources for various problems such as data storage and coordination as well as various applications such as regular Internet/cloud applications as well as ones based on machine learning and video analytics. Our most recent published projects are appearing in ICDE 2021 next week. In the following, I will give a brief overview of our three papers and pointers to where you can read/hear more about them.
The first project is CooLSM that is led by Natasha Mittal. In CooLSM, we study distributing storage across edge and cloud resources [4]. Our goal is to place storage tasks that need to be done in real-time — such as data ingestion and caching — close to users at the edge, while placing tasks that require more compute and storage — such as performing read queries, storing the full copy of data and recovery — at the cloud. We observe that Log-Structured Merge (LSM) trees capture this trade-off. In terms of edge concerns, LSM trees are designed to perform ingestion fast and keep the most recent data at the beginning of the path of execution (which can act as an LRU cache). In terms of cloud concerns, LSM leaves the heavy lifting (compaction and storage of large memory segments) to the higher LSM levels at the end of the path of execution. Starting from this observation, we build our distributed CooLSM storage by deconstructing the LSM tree structure and placing the low levels (responsible for ingestion and maintaining the “cache”) at the edge, and placing the rest of the levels (responsible for slow compaction and storage of large segments of data) at the cloud. We then augment this design by building a component to store backups that are placed at the cloud to process read-only queries away from nodes performing ingestions and compaction. The paper also explores using this deconstruction to scale compaction by dividing across machines. The combination of deconstructing LSM trees and adding backup nodes opens interesting questions in the performance-accuracy trade-off of such a distributed design. In the paper, we provide some ways to think of the consistency of operations of these distributed components.

The second project is WedgeChain [5]. WedgeChain tackles the challenge that edge nodes might be untrusted. This can be due to edge nodes running on infrastructure that is outside the trust domain of the application, or due to the challenges of less-capable edge devices that might be more susceptible to arbitrary software/hardware errors and malicious breaches. Existing solutions would do one of two things: (1) edge nodes would coordinate via a byzantine agreement protocol to tolerate malicious/arbitrary behavior, or (2) a trusted node — typically centralized in a public or private cloud — would authenticate every operation and data item and then send them to edge nodes to be served to users. The authentication — through data structures such as Merkle Trees — allows the potentially untrusted edge node to provide proof of the authenticity of the served data items. Both these approaches incur significant overhead, either due to extensive coordination of byzantine fault-tolerant protocols or due to large wide-area latency between the edge and the trusted entity. WedgeChain proposes relaxing trust requirements in the following way. Instead of having every data item to be authenticated synchronously with the trusted entity, authentication and certification of operation in the edge will be done lazily. Specifically, edge nodes are going to be allowed to act maliciously, however, record-keeping mechanisms will guarantee that malicious activity will be eventually detected. This eventual detection of malicious activity might be enough to deter nodes from acting maliciously in certain applications (for example, if the identity of the operator of the edge node is known and penalties on malicious actions outweigh the benefit of the malicious act.) We take this observation of lazy trust and build an indexing structure at the edge that builds an authenticated data structure lazily at the edge, getting inspirations from the structure of mLSM [6], which enables us to incrementally build an authenticated data structure lazily at the edge.
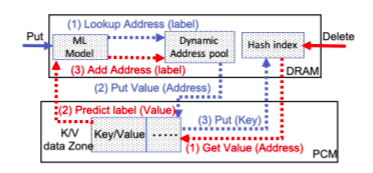
The third piece of work is Predict and Write (PnW) [7], led by Saeed Kargar. PnW tackles problems that are associated with NVM storage systems on edge devices: lifetime and energy efficiency. Although these two challenges are more significant for edge devices with less-capable hardware (and where maintenance incurs more overhead), PnW is designed to improve the lifetime and energy efficiency of general NVM storage systems. PnW, similar to some prior work, makes the observation that reducing the number of bit flips of a write operation to an NVM segment leads to reducing the wear on the memory segment and reducing the energy needed to perform the write operation. Prior methods proposed techniques to reduce bit flips by manipulating the bits of the written data to better match the content of the memory location that it is written to. Other methods aim to reduce the number of write operations to reduce the wear on NVM storage. PnW proposes to proactively pick memory locations for new write operations judiciously to reduce the number of bit flips. Specifically, PnW will find a memory location that is similar to the data item to be written. To this end, PnW builds a machine learning model that clusters free memory locations into clusters based on their hamming distance similarity. When a new write comes, the model picks a memory location from the cluster that is most similar to the content of the new write operation. PnW demonstrates that proactively choosing the free memory location for a new write operation has the potential of reducing the number of bit flips significantly.
We are excited by this year’s ICDE and are looking forward to presenting and discussing our edge-cloud work as well as the other wonderful papers in the ICDE program.
References:
[1] Paparrizos, John, Chunwei Liu, Bruno Barbarioli, Johnny Hwang, Ikraduya Edian, Aaron J. Elmore, Michael J. Franklin, and Sanjay Krishnan. “VergeDB: A Database for IoT Analytics on Edge Devices.” In CIDR 2021.
[2] Kang, Yiping, Johann Hauswald, Cao Gao, Austin Rovinski, Trevor Mudge, Jason Mars, and Lingjia Tang. “Neurosurgeon: Collaborative intelligence between the cloud and mobile edge.” ACM SIGARCH Computer Architecture News 45, no. 1 (2017): 615-629.
[3] Daniel Abadi, Anastasia Ailamaki, David Andersen, Peter Bailis, Magdalena Balazinska, Philip Bernstein, Peter Boncz, Surajit Chaudhuri, Alvin Cheung, AnHai Doan, Luna Dong, Michael J. Franklin, Juliana Freire, Alon Halevy, Joseph M. Hellerstein, Stratos Idreos, Donald Kossmann, Tim Kraska, Sailesh Krishnamurthy, Volker Markl, Sergey Melnik, Tova Milo, C. Mohan, Thomas Neumann, Beng Chin Ooi, Fatma Ozcan, Jignesh Patel, Andrew Pavlo, Raluca Popa, Raghu Ramakrishnan, Christopher Ré, Michael Stonebraker, and Dan Suciu. “The seattle report on database research.” ACM SIGMOD Record 48, no. 4 (2020): 44-53.
[4] Natasha Mittal, Faisal Nawab. “CooLSM: Distributed and Cooperative Indexing Across Edge and Cloud Machines”. In ICDE 2021.
[5] Faisal Nawab. “WedgeChain: A Trusted Edge-Cloud Store With Asynchronous (Lazy) Trust.” In ICDE 2021.
[6] Raju, Pandian, Soujanya Ponnapalli, Evan Kaminsky, Gilad Oved, Zachary Keener, Vijay Chidambaram, and Ittai Abraham. “mlsm: Making authenticated storage faster in ethereum.” In 10th {USENIX} Workshop on Hot Topics in Storage and File Systems (HotStorage 18). 2018.
[7] Kargar, Saeed, Heiner Litz, and Faisal Nawab. “Predict and Write: Using K-Means Clustering to Extend the Lifetime of NVM Storage.” In ICDE 2021.