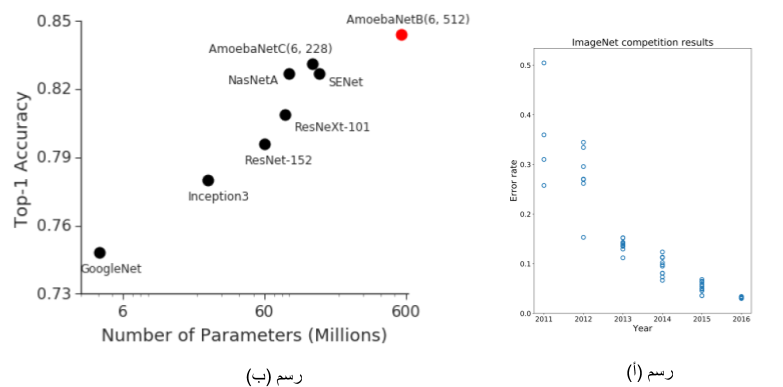
عند الاطلاع على الأبحاث في مجال تحليل البيانات و تعلم الآلة, ستلاحظ أن أحد أهم الأهداف هي زيادة دقة الاستنباط من خلال النموذج المقترح. على سبيل المثال, أحد المنافسات المشهورة في تعلم الآلة هي منافسة على إيجاد نماذج لمجموعة بيانات صور تسمى (ImageNet). للعديد من السنوات قام باحثين و عاملين في تعلم الآلة ببناء نماذج و أدوات لتحسين التعلم من مجموعة البيانات و الوصول لدقة أفضل. الرسم (أ) في الأسفل يبين كيف أنه في خلال خمس سنوات, تحسنت دقة النماذج من حوالي 25% استنباطات خاطئة إلى 5% فقط من الاستنباطات الخاطئة. هذه القفزات الكبيرة كانت نتاج نماذج و أدوات ركزت على “الدقة” كأهم معيار. و لكن, الدقة ليست كل شيء. و السباق نحو نماذج ذات دقة أكبر قد يكون توجها خاطئا للاستخدامات العملية.
التبعات السلبية للنماذج ذات الدقة الأكبر
أحد الظواهر ذات التبعات السلبية المترتبة على الرغبة في نماذج ذات دقة أعلى هي نماذج ذات حجم و تعقيد حسابي أكبر. عودة إلى مثال مجموعة بيانات الصور (ImageNet), التحسن في الدقة هو على علاقة مع الزيادة في حجم النموذج (الرسم (ب) في الأعلى يظهر العلاقة بين حجم النموذج في الإحداثية السينية و الدقة في الإحداثية الصادية.) التبعات السلبية لنموذج بحجم أكبر هي في الأمور العملية لاستخدام هذه النماذج, مثلا:
1- نموذج بحجم أكبر يحتاج إلى أجهزة بذاكرة أكبر: و بسبب أن استخدام النموذج يتطلب قراءة جميع المعطيات, فإن المتوقع أن النموذج سيكون بكامله موجوداً في الذاكرة الأساسية. هذا يعني أن الأجهزة الصغيرة و الطرفية قد لا تتمكن من استخدام هذه النماذج. هذه السلبية مهمة لأن الكثير من تطبيقات الذكاء الصناعي تستهدف أنظمة من هذا النوع (مثلاً, التعرف اللحظي على الصور في كاميرات المراقبة تتطلب أن يكون التعرف في الكاميرا نفسها ذات الإمكانيات المحدودة.)
2- نموذج بحجم و تعقيد أكبر يحتاج إلى وقت أطول للمعالجة أو أجهزة ذات سعر عالي: هذا بسبب أن استخدام النموذج يتطلب القيام بالكثير من العمليات الرياضية و التي تأخد وقتا طويلا للنماذج الكبيرة. هذا يجعل الاستخدامات العملية لهذه النماذج بين خيارين: إما التعايش مع وقت معالجة طويل أو شراء أجهزة و معدات ذات أسعار عالية. على سبيل المثال, تتطلب المعالجة اللحظية للصور من كاميرات المراقبة إمكانية معالجة 30 صورة في الثانية. عندما جربت نموذج لمعالجة الصور على جهازي, كل صورة احتاجت ثانية كاملة للمعالجة! في الطريق الآخر, لمعالجة 30 صورة في الثانية أحتاج إلي شراء مجموعة من أجهزة GPU تصل تكلفتها لآلاف الدولارات.
تفادي سلبيات النماذج الكبيرة و الاهتمام بالخواص العملية
لتفادي هذه السلبيات, يجب أن يكون هناك اهتمام بالنواحي العملية بالإضافة لدقة النموذج. مثلا, للتطبيقات في الحوسبة الطرفية يمكن أن يتم تحديد حجم النموذج عند تطويره. و بالإضافة لعامل الدقة, يمكن إضافة العامل المالي عند تطوير نماذج جديدة (ما سعر الأجهزة اللازمة ليعمل النموذج بشكل جيد أو كم سعر الأجهزة السحابية لتقوم بالمعالجة بالكمية المطلوبة.) جميع هذه الأسئلة قد بدأ البحث عنها من مجموعات بحثية مختلفة. في الكثير من الحالات مجرد تضمين هذه النواحي العملية في مرحلة تدريب نموذج تعليم الآلة يكون له تأثير كبير.
طريقة أخرى لتخطي السلبيات هو بناء برمجيات معالجة البيانات و النماذج بطرق تجعل المعالجة أسرع أو أكثر كفاءة, مثل:
1- استخدام النموذج الأساسي (الكبير الحجم) لبناء نموذج أصغر مخبأ: استخدام النموذجين (الأساسي و الصغير) معا قد يمكننا من معالجة البيانات بشكل سريع و دقيق. يمكن ذلك باستخدام النموذج الصغير (و الذي سيكون أسرع) كمرحلة أولى. إذا كانت النتيجة من النموذج الصغير ذات ثقة عالية فالمعالجة تنتهي. أما إذا كانت الثقة منخفضة فيتم استخدام النموذج الأساسي. الذي يحدث في هذا الترتيب للنماذج هو شبيه بفكرة الذاكرة المخبأة (caching) حيث يكون هناك ذاكرة صغيرة و لكن سريعة تستخدم أولا, و ذاكرة أكبر و لكن أبطأ في حال أن الذاكرة الصغيرة لم تكفي. عن طريق ترتيب النماذج, يمكن معالجة الكثير من البيانات بالنموذج الصغير فقط, مما يجعل وقت المعالجة الكلي أسرع.
2- الاستفادة من التحليلات السابقة لتحليل البيانات الجديدة: في تطبيقات عديدة, هناك تكرار للبيانات التي يتم معالجتها. على سبيل المثال, في البيانات من كاميرات المراقبة, هناك حالات كثيرة تكون فيها الصورة ثابتة و لا تتغير إلا تغييرات طفيفة. في حال أن الخوارزمية وجدت أن الصورة الحالية هي شبيهة بدرجة كبيرة بالصورة السابقة, يمكن استخدام نتائج التحليل السابقة مباشرة.
تحليل البيانات و نماذج تعلم الآلة في الحوسبة الطرفية
بشكل عام, هناك فرص كثيرة لتطبيق هذه الطرق و الأدوات و تكييفها لمجالات معينة. أحد المجالات الواعدة لطرق معالجة متخصصة هي تطبيقات الحوسبة الطرفية. الحوسبة الطرفية هي مجال واعد لتطبيقات تحليل البيانات و تعلم الآلة. بالإضافة لذلك, هناك تحديات بحثية و عملية مهمة و مثيرة لتطبيق حلول تحليل البيانات و تعلم الآلة في الحوسبة الطرفية.
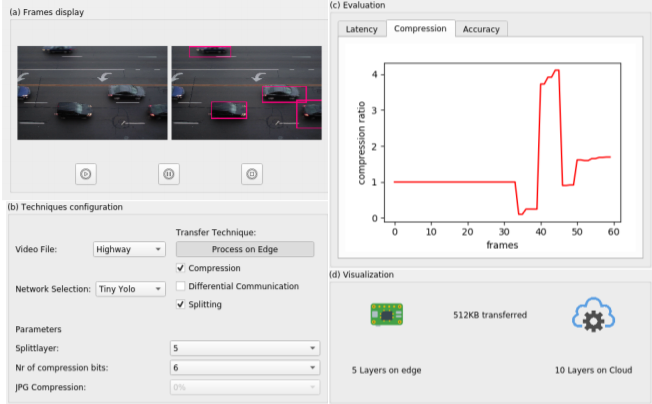
الواجهة للمشروع الذي قمنا به لدراسة تأثير طرق لتحسين تطبيقات تعلم الآلة على النظم الموزعة بين الحوسبة الطرفية و السحابية
لهذا السبب قمنا بمشروع لاختبار بعض الطرق لتحسين معالجة نماذج تعلم الآلة في الحوسبة الطرفية. بالتحديد, قمنا بالبحث عن طرق تناسب الأنظمة الموزعة في الحوسبة الطرفية و السحابية (بمعنى أن هناك أجهزة محدودة الامكانيات في الحوسبة الطرفية تقوم بالتعاون مع أجهزة ذات امكانيات أكبر في الحوسبة السحابية). الطرق التي قمنا بدراستها هي:
1- فصل النماذج: أحد الطرق المقترحة سابقا هي فصل نموذج تعلم الآلة (شبكة عصبونية التفافية في هذه الحالة) إلى جزئين, أحدهما في الطرف و الآخر في السحابة. البيانات يتم تحليلها مبدئيا في الجزء الطرفي و يتم إكمال التحليل في الجزء السحابي. إذا تم الفصل بشكل جيد, فإن التحليل بهذه الطريقة يكون أسرع.
2- تحليل الفرق بين البيانات الجديدة و القديمة: عوضا عن تحليل كل مجموعة بيانات جديدة على حدى, فإننا نحلل الفرق بين البيانات الجديدة و القديمة فقط. هذا يوفر علينا نقل البيانات كاملة إلى السحابة و يوفر وقت تحليل البيانات المكررة.
3- ضغط البيانات (compression): عند إرسال البيانات, نقوم بضغطها أولا لتوفير نقل البيانات إلى السحابة.
في المشروع قمنا باختبار القيام بدمج هذه الطرق سويا. الرسم في الأعلى يبين واجهة المشروع التي تقوم باختبار الطرق المختلفة على مقاطع من كاميرات مراقبة. في بعض الأحيان, الدمج لم يكن بديهيا, مثل الدمج بين فصل النماذج و تحليل الفرق, بما أن الفرق يتم حسابه لمرحلة داخل نموذج تعلم الآلة. للمهتمين بهذا المشروع, الورقة البحثية يمكن دخولها من الرابط (الورقة تشير إلى الأبحاث التي اقترحت الطرق المعروضة في التدوينة): http://www.vldb.org/pvldb/vol11/p2046-grulich.pdf
و المصدر البرمجي للمشروع موجود على الرابط: https://github.com/PhilippGrulich/Collaborative-Realtime-Object-Detection
مصادر
1. الرسم (ب): https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html
2. وصف مشروع نظام موزع بين الحوسبة الطرفية و السحابية لتطبيقات تعلم اﻵلة و يحتوي على اشارات لمصادر الأبحاث التي تحدثت عنها في هذه التدوينة: http://www.vldb.org/pvldb/vol11/p2046-grulich.pdf